
https://www.linkedin.com/pulse/introduction-large-language-models-transformer-pradeep-menon/
2. what is transformers Architecture that is used in LLM?
https://jalammar.github.io/illustrated-transformer/
https://www.linkedin.com/pulse/introduction-large-language-models-transformer-pradeep-menon/
The Transformer architecture is a cornerstone of modern large language models (LLMs) such as GPT-3 and BERT. Introduced by Vaswani et al. in the paper “Attention is All You Need” (2017), the Transformer architecture has revolutionized natural language processing (NLP) by providing a framework that can handle long-range dependencies more effectively than previous models like RNNs and LSTMs. Here’s a detailed explanation of the Transformer architecture, suitable for an interview context:
Transformer Architecture Overview
The Transformer architecture is designed around the concept of self-attention mechanisms, which allow the model to weigh the importance of different words in a sequence dynamically. It consists of an encoder and a decoder, each composed of multiple layers.
Key Components
- Self-Attention Mechanism: This mechanism allows the model to focus on different parts of the input sequence when encoding a particular word. It captures dependencies regardless of their distance in the sequence.
- Multi-Head Attention: Instead of applying a single self-attention mechanism, the model uses multiple attention heads to capture different aspects of the relationships between words.
- Positional Encoding: Since Transformers do not inherently understand the order of sequences, positional encodings are added to input embeddings to provide information about the position of words.
- Feed-Forward Neural Networks: Each layer in the encoder and decoder contains a fully connected feed-forward network, applied independently to each position.
- Layer Normalization and Residual Connections: These techniques are used to stabilize training and improve gradient flow.
Detailed Structure
Encoder
The encoder is responsible for processing the input sequence and consists of multiple identical layers (typically 6-12). Each layer has two main sub-layers:
- Multi-Head Self-Attention:
- Splits the input into multiple heads, applies self-attention to each, and then concatenates the results.
- This allows the model to attend to different parts of the sequence simultaneously.
- Feed-Forward Neural Network:
- Applies two linear transformations with a ReLU activation in between.
- This adds non-linearity and helps in learning complex patterns.
Decoder
The decoder generates the output sequence, also consisting of multiple identical layers. Each layer has three main sub-layers:
- Masked Multi-Head Self-Attention:
- Similar to the encoder’s self-attention but masks future tokens to prevent the model from “cheating” by looking ahead.
- Multi-Head Attention (Encoder-Decoder Attention):
- Attends to the encoder’s output, allowing the decoder to focus on relevant parts of the input sequence.
- Feed-Forward Neural Network:
- Same as in the encoder, applies two linear transformations with a ReLU activation.
Transformer Block Diagram

Self-Attention Mechanism
Calculation
- Inputs: Queries (Q), Keys (K), and Values (V), all derived from the input embeddings.
- Attention Scores: Calculated as:
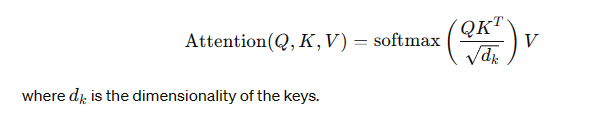
- Softmax Function: Ensures that the attention scores are probabilities that sum to 1.
Multi-Head Attention
- Multiple Heads: Apply self-attention multiple times with different linear projections of (Q), (K), and (V).
- Concatenation and Linear Transformation: Concatenate the outputs of all attention heads and pass through a linear transformation.
Key Advantages
- Parallelization: Unlike RNNs, Transformers process the entire sequence simultaneously, allowing for greater parallelization and faster training.
- Long-Range Dependencies: Self-attention mechanisms can capture long-range dependencies more effectively than RNNs.
- Scalability: The architecture scales well with larger datasets and more computational resources, making it ideal for training very large models.
Use-Cases in Large Language Models
- GPT (Generative Pre-trained Transformer): Uses a decoder-only architecture for autoregressive text generation.
- Pre-training: Trained on a large corpus of text to predict the next word in a sequence.
- Fine-tuning: Adapted to specific tasks with supervised fine-tuning.

- BERT (Bidirectional Encoder Representations from Transformers): Uses an encoder-only architecture for masked language modeling and next sentence prediction.
- Pre-training: Trained on masked language modeling (predicting masked words) and next sentence prediction tasks.
- Fine-tuning: Adapted to various NLP tasks such as question answering and text classification.

Comparison with Other Architectures
| Feature | Transformers | RNNs/LSTMs | CNNs (for sequence tasks) |
|---|---|---|---|
| Parallel Processing | Yes | No | Yes |
| Long-Range Dependencies | Excellent (Self-Attention) | Limited (Vanishing Gradient) | Moderate |
| Scalability | High | Moderate | High |
| Training Speed | Fast | Slow | Fast |
| Interpretability | Good (Attention Weights) | Poor | Poor |
Further Reading and URLs
- Attention is All You Need (Original Paper): arXiv
- The Illustrated Transformer: jalammar.github.io
- OpenAI GPT-3: OpenAI GPT-3
- Understanding BERT: Google AI Blog
- Transformers in Deep Learning: Towards Data Science
By understanding the Transformer architecture, its components, and how it compares to other models, you gain a comprehensive view of why it has become the backbone of state-of-the-art language models in NLP.
Transformer Models
13. How do transformer architectures contribute to advancements in Generative AI?
Transformer architectures have significantly contributed to advancements in Generative AI, particularly in the field of Natural Language Processing (NLP) and Computer Vision. Here are some ways transformers have impacted Generative AI:
- Sequence-to-Sequence Models: Transformers have enabled the development of sequence-to-sequence models, which can generate coherent and meaningful text. This has led to significant improvements in machine translation, text summarization, and chatbots.
- Language Generation: Transformers have been used to generate text that is more coherent, fluent, and natural-sounding. This has applications in areas like content generation, dialogue systems, and language translation.
- Image Generation: Transformers have been used in computer vision tasks, such as image generation and manipulation. This has led to advancements in applications like image-to-image translation, image synthesis, and style transfer.
- Conditional Generation: Transformers have enabled the development of conditional generation models, which can generate text or images based on specific conditions or prompts. This has applications in areas like product description generation, image captioning, and personalized content generation.
- Improved Modeling Capabilities: Transformers have enabled the development of more complex and nuanced models, which can capture long-range dependencies and contextual relationships in data. This has led to improvements in tasks like language modeling, sentiment analysis, and text classification.
- Parallelization: Transformers can be parallelized more easily than other architectures, which has led to significant speedups in training times and improved scalability.
- Attention Mechanism: The attention mechanism in transformers has enabled the model to focus on specific parts of the input sequence, which has improved the model’s ability to generate coherent and relevant text or images.
- Pre-training: Transformers have enabled the development of pre-trained language models, which can be fine-tuned for specific tasks. This has led to significant improvements in many NLP tasks.
- Multimodal Generation: Transformers have enabled the development of multimodal generation models, which can generate text, images, or other forms of media. This has applications in areas like multimedia summarization, image captioning, and video summarization.
- Advancements in Adversarial Training: Transformers have enabled the development of more effective adversarial training techniques, which can improve the robustness of the model to adversarial attacks.
In summary, transformer architectures have significantly contributed to advancements in Generative AI by enabling the development of more powerful and nuanced models, improving the quality and coherence of generated text and images, and enabling the creation of more complex and realistic data.
Short Summay
To explain the Transformer architecture from the “Attention Is All You Need” paper in a clear and concise way, focus on the key concepts and components without delving into the intricate mathematical details. Here’s a structured way to explain it:
1. Introduction to Transformers
The Transformer is a deep learning model introduced by Vaswani et al. in 2017. It is designed primarily for handling sequential data and has become the foundation for many state-of-the-art models in natural language processing (NLP).
2. Core Idea: Attention Mechanism
The central innovation of the Transformer is the attention mechanism. Unlike previous models, such as RNNs and LSTMs, which process data sequentially, the Transformer can process data in parallel, making it more efficient.
3. Components of the Transformer Architecture
The Transformer model is composed of an encoder and a decoder.
Encoder
- Input Embedding: Converts input tokens into vectors of a fixed size.
- Positional Encoding: Adds information about the position of each token in the sequence since the model doesn’t process data sequentially.
- Self-Attention Mechanism: Allows the model to focus on different parts of the input sequence when encoding a particular token. It computes a weighted average of all tokens’ representations in the sequence.
- Feed-Forward Neural Network: Applies a simple neural network to each position independently.
- Residual Connections and Layer Normalization: Helps in training deeper networks by adding the input of a layer to its output (residual connections) and normalizing the output.
Decoder
- Output Embedding and Positional Encoding: Similar to the encoder.
- Masked Self-Attention: Ensures that the model only attends to earlier positions in the output sequence during training.
- Encoder-Decoder Attention: Allows the decoder to focus on relevant parts of the input sequence.
- Feed-Forward Neural Network: Same as in the encoder.
- Residual Connections and Layer Normalization: Same as in the encoder.
4. Attention Mechanisms in Detail
There are different types of attention in the Transformer:
- Self-Attention (or Intra-Attention): Used in both the encoder and decoder to consider other tokens in the sequence.
- Encoder-Decoder Attention: Used in the decoder to focus on relevant parts of the encoded input sequence.
5. Self-Attention Calculation
Briefly explain the self-attention mechanism:
- Each token is transformed into three vectors: Query (Q), Key (K), and Value (V).
- The attention score is computed by taking the dot product of Q and K, followed by a softmax operation to get the weights.
- These weights are then used to compute a weighted sum of the Value vectors.
6. Benefits of the Transformer
- Parallelization: Unlike RNNs, the Transformer can process all tokens in a sequence simultaneously, allowing for faster training.
- Long-Range Dependencies: The attention mechanism enables the model to capture long-range dependencies effectively.
7. Conclusion
Transformers revolutionized NLP by addressing the limitations of previous sequential models and have become the standard for tasks like machine translation, text summarization, and more.
By sticking to this high-level overview, you convey a solid understanding of the Transformer architecture without getting bogged down in too many details.
Deep Dive into Decoder side
Great question! Understanding how the encoder’s output is used by the decoder is crucial for grasping the full Transformer architecture. Here’s a straightforward explanation:
How the Encoder’s Output is Used by the Decoder
The encoder’s output, which consists of the contextually enriched representations of the input sequence, is utilized by the decoder in the following ways:
- Encoder-Decoder Attention Layer:
- The primary way the encoder’s output is used in the decoder is through the encoder-decoder attention layer.
- In this layer, each position in the decoder’s input attends to all positions in the encoder’s output.
- This allows the decoder to incorporate information from the entire input sequence, which helps in generating accurate and contextually relevant outputs.
Structure of the Decoder
To understand this better, let’s break down the decoder’s layers:
- Masked Self-Attention Layer:
- This layer allows each position in the decoder to attend to earlier positions in the output sequence. It ensures that the prediction for a particular position depends only on the known outputs before it.
- This layer does not directly use the encoder’s output.
- Encoder-Decoder Attention Layer:
- After the masked self-attention layer, the output is passed to the encoder-decoder attention layer.
- In this layer, the queries (Q) come from the previous layer (masked self-attention output), while the keys (K) and values (V) come from the encoder’s output.
- This mechanism helps the decoder decide which parts of the input sequence to focus on when generating each token in the output sequence.
- Feed-Forward Neural Network:
- Similar to the encoder, the output of the encoder-decoder attention layer is passed through a feed-forward neural network, followed by residual connections and layer normalization.
Summary
- Encoder’s Output in Decoder: The encoder’s output is used in the encoder-decoder attention layer of the decoder.
- Self-Attention in Decoder: The self-attention layer in the decoder does not directly use the encoder’s output; instead, it focuses on the partial output sequence generated so far.
- Function of Encoder-Decoder Attention: This layer enables the decoder to leverage information from the entire input sequence, thus aiding in generating contextually accurate and coherent output tokens.
By understanding these roles, you can clearly explain how the encoder’s output is integrated into the decoding process, ensuring the model produces meaningful and relevant outputs based on the input sequence.
#